

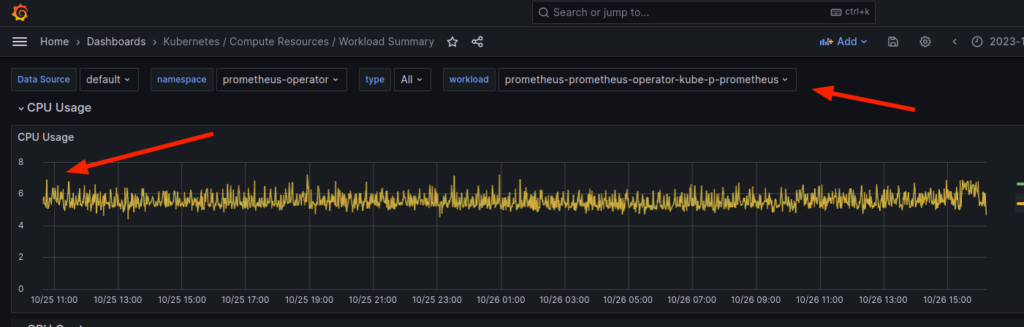
Небольшая предыстория. Есть Prometheus, который запущен в k8s кластере и на нём большая нагрузка по CPU, хотя достаточно не много ресурсов скрейпятся в единицу времени (около 200к таймсерий каждые 10 сек). Картина нагрузки выглядит следующим образом:
curl -s https://prometheus.prometheus-operator.svc.cluster.local/api/v1/rules | jq '.data.groups[] | .name, .evaluationTime'В получившемся результате, меня заинтересовала группа node-exporter т.к. она выполнялась много времени
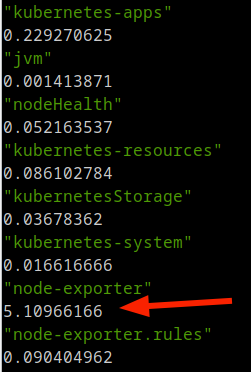
Теперь, я хочу понять, какое правило в этой группе больше всего отрабатывает. Для этого, вытаскиваю все рулесы с этой группы и смотрю детально
curl -s https://prometheus.prometheus-operator.svc.cluster.local/api/v1/rules | jq '.data.groups[] | select(.name == "node-exporter") | .rules[] | .name, .evaluationTime'Основные правила, которые жрут ресурсы CPU / Mem / Disk (нужное подчеркнуть) Имеют высокий уровень времени выполнения.
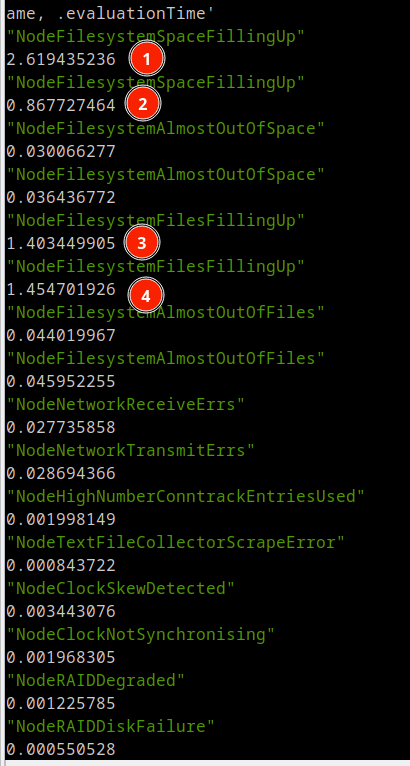
Вот они и попались. Далее, идём и смотрим, что за правила, нужны ли они нам и можем ли мы их соптимизировать.
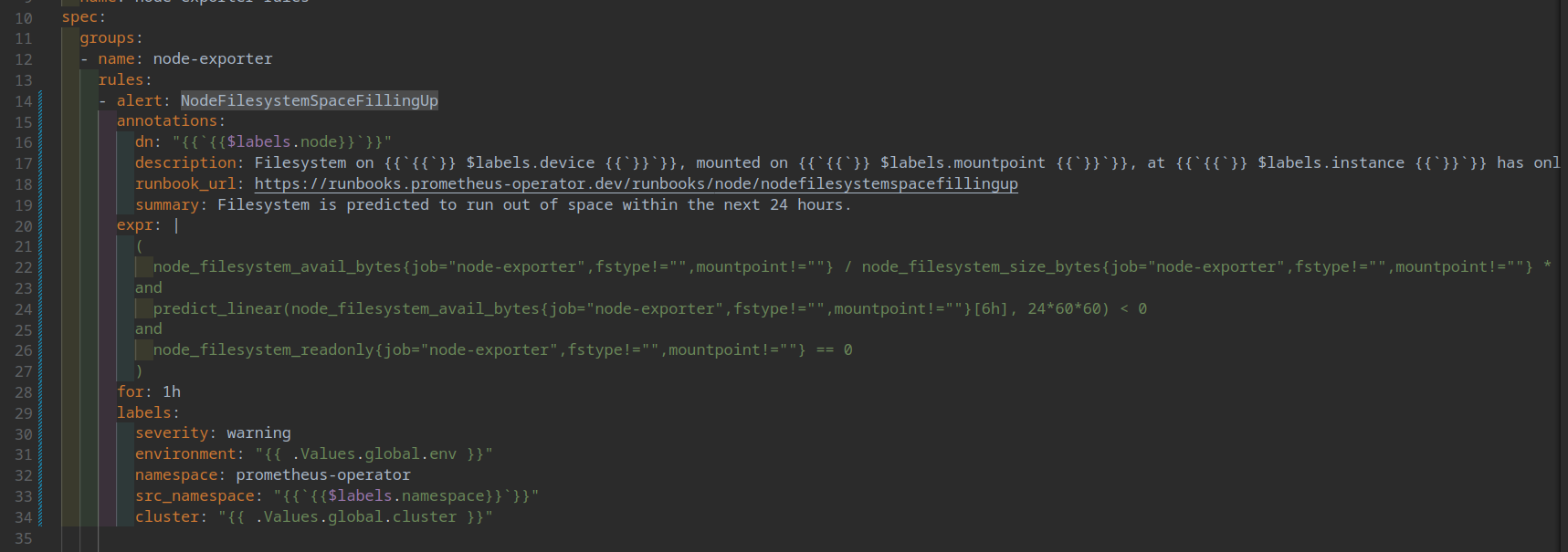
В моём случае, это были правила предсказаний, что диск или inodes закончаться в течении 24 часов, если линейная динамика , которая была за последнии 6 часов будет примерно такой-же и если диск забит буже более,чем на 85%. Опять же, для меня, это не критичный алерт, т.к. на 85% для меня уже пора бить тревогу и разбираться (на регулярных инстансах, а не на 100500Тб дисках). В Вашем случае, вероятно, придёться разбираться и оптимизировать запросы, но у себя, я просто деактивировал эти 4 правила и картина сильно стала лучше:
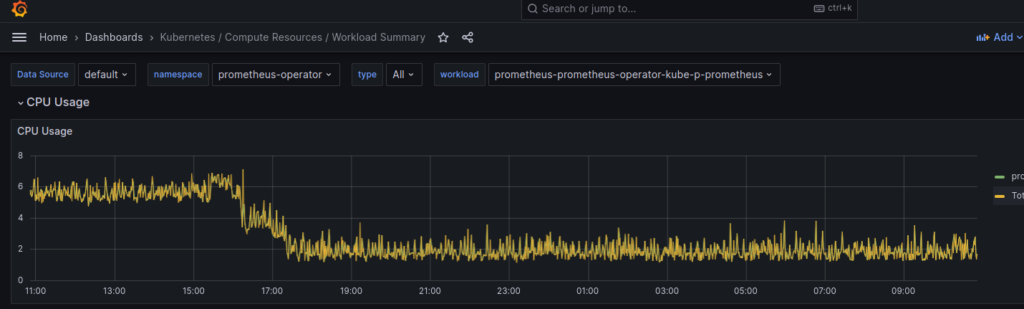
2 CPU ядра против 6!
PROFIT